Machine learning (ML) is a subset of artificial intelligence (AI) that uses reinforcement learning with human-like levels of intelligence to predict outcomes and improve task performance. ML is widely applied in healthcare, including pharmacy practices. It can be used to calculate dosages in special populations that are difficult for traditional human computing.
There are, however, challenges in data management and analytics, and special skill sets are needed when working with ML in drug dosing applications.
Pharmacokinetic (PK) Drug Dosing
Drug dosing involves building a suitable model in an attempt to determine how the medication is distributed throughout the body and how the body eliminates the medication. The current most utilized method for calculating dosages for critical or potentially toxic medications is pharmacokinetic (PK) drug dosing. PK dosing involves building a compartmental model, which assumes that the drug will be present in a particular compartment of the body with a relatively uniform concentration. The goal of PK drug dosing is to find a therapeutic dose of a particular medication that will give the desired effect while avoiding adverse effects due to toxic levels of the medication.
Role of Machine Learning in Drug Dosing
PK dosing works well as long as the patient fits the population included in developing a particular model. However, many patient populations do not fit the traditional PK models due to physical differences such as spinal cord injury or genetic differences. Spinal cord injuries are susceptible to changes in body mass index (BMI), in blood perfusion, in kidney function, and alteration in gastrointestinal absorption, all of which may result in invalidation of PK dosing.1
ML may fill the gap in these underserved population groups. One study used an ML algorithm to build a decision tree to improve first doses of vancomycin, which resulted in higher rates of achieving therapeutic levels than traditional dosing strategies.2 Other studies showed promise using ML in dosing warfarin in minority groups that are not normally included in PK modeling studies.3,4
The difference between ML and traditional programming is in the order of operations. In traditional programming, both data and the rules that make up the computer program are input into the system, and a result or output is returned. In ML, both the data and the result are used as input, and the system “learns” the rules for the program. (See Figure 1.)
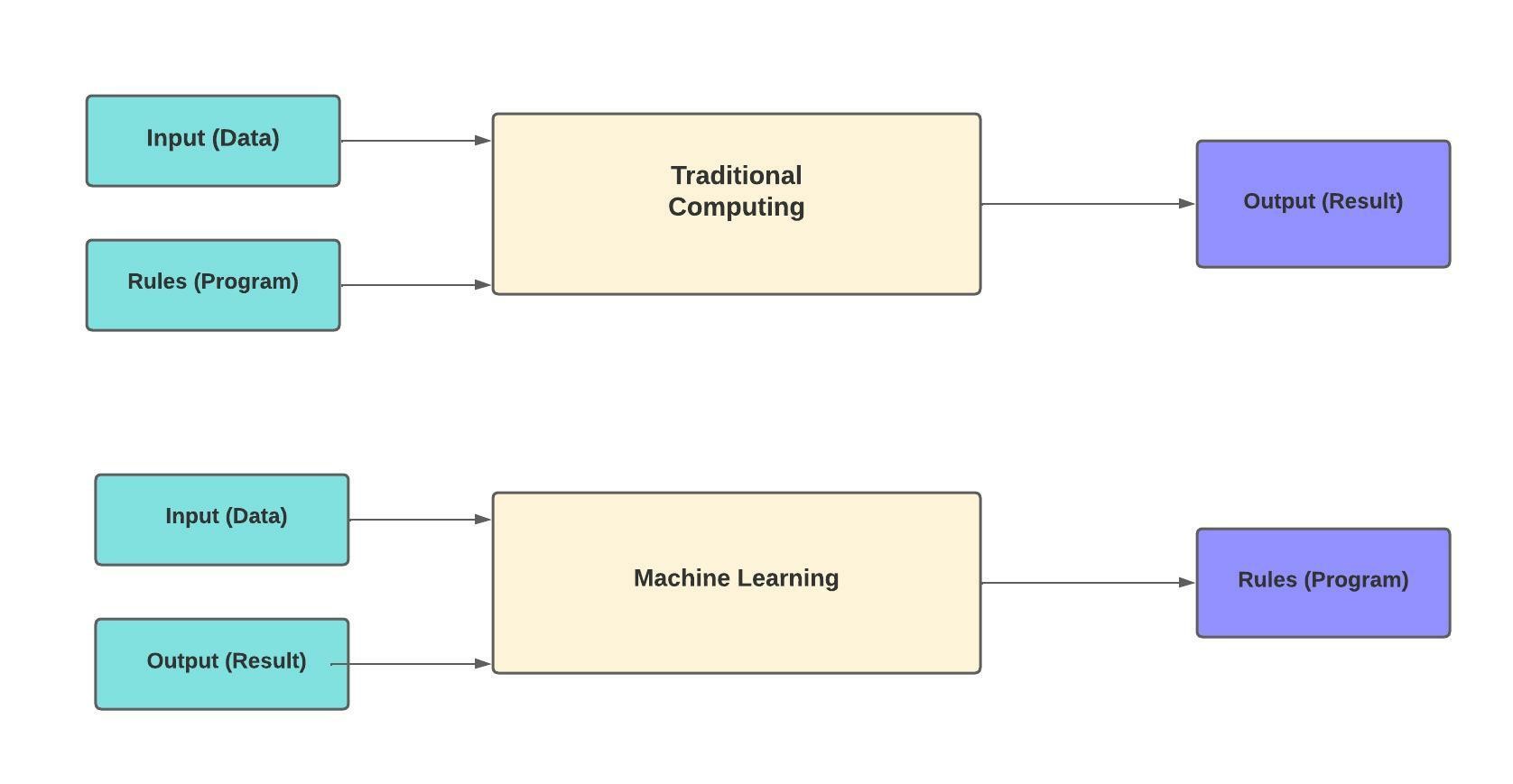
Figure 1: Traditional Computing vs. Machine Learning
A PK drug dosing model takes years to develop and is only representative of the population that is included in the research. If a patient does not fit the established PK model, the clinician will have to use clinical experience and judgement to determine an appropriate dose. In contrast, a ML model can be developed quickly and include subgroups of populations. The model will use patient specific values, such as BMI, lab tests for kidney and liver function, protein levels, as data input (also known as features), as well as the drug levels after previous drug administrations as a target. The ML model will find correlations of the features to the target value during the training phase, and then can be used to predict future drug doses. In addition, the predictions can feed back to the model to improve the performance. (See Figure 2.)
Figure 2: PK Dosing vs. Machine Learning Dosing
Challenges of Data Quality for Machine Learning
When considering building an ML model for a clinical application such as drug dosing, it is tempting to get caught up in the technical details such as the selection of an algorithm, model training strategies, and parameter tuning; however, data validation remains the key to success.5
Consider building an ML model to predict a first dose of gentamicin to treat urinary tract infections (UTI) in spinal cord injury patients. When the training dataset is created, critical information may be missing or incorrect. For example, measuring start time and duration of gentamicin infusion may be entered incorrectly. This would render predictions from a model built on this dataset unreliable no matter what model or features are used.
Quality of the data including accuracy, timeliness, and precision is all-important when working with ML model buildings.
Skills Needed for Machine Learning
Some basic technical skills are needed when working with ML. Those skills include applied mathematics, computer science fundamentals and programming, data modeling and evaluation, algorithms used in ML, and natural language processing. Soft skills are also necessary characteristics for delivering your technical skills more effectively.
Mathematics, such as linear algebra, probability, statistics, and multivariate calculus, are fundamental skills in ML. When selecting the appropriate ML algorithm, mathematical formulas, parameters, approximate confidence levels, and statistical modeling procedures are all basic concepts to apply. Fundamental computer science, such as data structures, algorithms, space and time complexity, and different programming languages like R and Python for ML and SQL for database management, is another important skill for ML.
Data in general are fundamental constructs for ML. When building data modeling, it involves data structures, and the patterns of the data. For example, the drug dosing discussed above require understanding of regression, classification, clustering, dimension reduction, and clinical terminology and concepts. A basic understanding of algorithms, such as decision tree, linear regression, and neural networks is also needed for ML.
Soft skills in ML such as communication, problem-solving, and critical thinking are equally important when working with ML to convey your technical skills to non-technical people, solve ongoing problems, and make better decisions.
HI’s Role in ML
With the rise in pharmacogenomics and precision medicine, the use of ML will likely rise as well. ML modeling in healthcare is promising, but unstructured or non-standardized data is still a remaining problem. Health information and informatics professionals, with appropriate skills, knowledge, and experience can play an important role in ML. Making sure that data for ML models are validated and up to date will add valuable assets to this widely and rapidly developing field.
Notes
1. Mestre H, Alkon T, Salazar S, Ibarra A. Spinal cord injury sequelae alter drug pharmacokinetics: an overview. Spinal cord. 2011;49(9):955-60.
2. Imai S, Takekuma Y, Miyai T, Sugawara M. A new algorithm optimized for initial dose settings of vancomycin using machine learning. Biological and Pharmaceutical Bulletin. 2020;43(1):188-93.
3. Shakeel D, Mir SA. Personalized drug concentration predictions with machine learning: An exploratory study. Int J Basic Clin Pharmacol. 2020;9:980.
4. Cosgun E, Limdi NA, Duarte CW. High-dimensional pharmacogenetic prediction of a continuous trait using machine learning techniques with application to warfarin dose prediction in African Americans. Bioinformatics. 2011;27(10):1384-9.
5. Breck E, Polyzotis N, Roy S, Whang S, Zinkevich M, editors. Data Validation for Machine Learning. MLSys; 2019.
AHIMA22 Presentation
Shannon Houser is presenting “Solutions for Challenges in Telehealth Privacy and Security” on Tuesday, October 11, at AHIMA22.
Shannon H. Houser (shouser@uab.edu) is a professor of health services administration at the University of Alabama at Birmingham.
R. Jeffrey Harris (rjh2002@uab.edu) is a registered pharmacist and Master of Science in Health Informatics student at the University of Alabama at Birmingham, to graduate August 2022.
By Shannon H. Houser, PhD, MPH, RHIA, FAHIMA, and R. Jeffrey Harris, RPH, MSHI
Take the CE Quiz